
Note: This post will probably not be on the liking of those who think free software is always preferable to closed source software, so if you are such a person, please take this article as an invitation to implement better open source alternatives that can realistically compete with the closed source applications I am mentioning here. I am not going to mention here where the open source alternatives are not up to the same level as the commercial tools, I'll leave that for the readers or for another article.
Semanticmerge is a merge tool that attempts to do the right thing when it comes to merging source code. It is language aware and it currently supports Java and C#. Just today the creators of the software have
started working on the support for C.
Recently they added Debian packages, so I installed it on my system. For open source development Codice Software, the creators of Semanticmerge, offers free licenses, so I decided to ask for one today, and, although is Sunday, I received an answer and I will get my license on Monday.
When a method is moved from one place to another and changed in a conflicting way in two parallel development lines, Semanticmerge can isolate the offending method and can pass all its incarnations (base, source and destination or, if you prefer, base, mine and theirs) to a text based merge tool to allow the developer to decide how to resolve the merge. On Linux, the Semanticmerge samples are using
kdiff3 as the text-based merge tool, which is nice, but I don't use kdiff3, I use
Meld, another open source visual tool for merges and comparisons.
OTOH,
Beyond Compare is a merge and compare tool made by Scooter Software which provides a very good text based 3-way merge with a 3 sources + 1 result pane, and can compare both files and directories. Two of its killer features is having the ability split differences into important and non-important ones according to the syntax of the compared/merged files, and the ability to easily change or add to the syntax rules in a very user-friendly way. This allows to easily ignore changes in comments, but also basic refactoring such as variable renaming, or other trivial code-wide changes, which allows the developer to focus on the important changes/differences during merges or code reviews.
Syntax support for usual file formats like C, Java, shell, Perl etc. is built in (but can be modified, which is a good thing) and new file types with their syntaxes can be added via the GUI from scratch or based on existing rules.
I evaluated Beyond Compare at my workplace and we decided it would be a good investment to purchases licenses for it for the people in our department.
Having these two software separate is good, but having them integrated with each other would be even better. So I decided I would try to see how it can be done. I installed Beyond compare on my system, too and looked through the examples
The first thing I discovered is that the main assumption of Semanticmerge developers was that the application would be called via the SCM when merges are to be done, so passing lots of parameters would not be problem. I realised that when I saw how one of the samples' starting script invoked semantic merge:
semanticmergetool -s=$sm_dir/src.java -b=$sm_dir/base.java -d=$sm_dir/dst.java -r=/tmp/semanticmergetoolresult.java -edt="kdiff3 \"#sourcefile\" \"#destinationfile\"" -emt="kdiff3 \"#basefile\" \"#sourcefile\" \"#destinationfile\" --L1 \"#basesymbolic\" --L2 \"#sourcesymbolic\" --L3 \"#destinationsymbolic\" -o \"#output\"" -e2mt="kdiff3 \"#sourcefile\" \"#destinationfile\" -o \"#output\""
Can you see the problem? It seems Semanticmerge has no persistent knowledge of the user preferences with regards to the text-based merge tool and exports the issue to the SCM, at the price of overcomplicating the command line. I already mentioned this issue in my license request mail and added
the issue and my fix suggestion in their voting system of features to be implemented.
The upside was that by comparing the command line for kdiff3 invocations, the
kdiff3 documentation and, by comparison, the Beyond Compare SCM
integration information, I could deduce what is the command line necessary for Semanticmerge to use Beyond Compare as an external merge and diff tool.
The -edt, -emt and -e2mt options are the ones which specify how the external diff tool, external 3-way merge tool and external 2-way merge tool is to be called. Once I understood that, I split the problem in its obvious parts, each invocation had to be mapped, from kdiff3 options to beyond compare options, adding the occasional bell and whistle, if possible.
The parts to figure out, ordered by compexity, were:
- -edt="kdiff3 \"#sourcefile\" \"#destinationfile\"
- -e2mt="kdiff3 \"#sourcefile\" \"#destinationfile\" -o \"#output\""
- -emt="kdiff3
\"#basefile\" \"#sourcefile\" \"#destinationfile\" --L1
\"#basesymbolic\" --L2 \"#sourcesymbolic\" --L3 \"#destinationsymbolic\"
-o \"#output\""
Semantic merge integrates with kdiff3 in diff mode via the
-edt option. This was easy to map to Beyond Compare, I just replaced kdiff3 with bcompare:
-edt="bcompare \"#sourcefile\" \"#destinationfile\""
Integration for 2-way merges was also quite easy, the mapping to Beyond Compare was:
-e2mt="bcompare \"#sourcefile\" \"#destinationfile\" -savetarget=\"#output\""
For the 3-way merge I was a little confused because the Beyond Compare documentation and options were inconsistent between Windows and Linux. On Windows, for some of the SCMs, the options that set the titles for the panes are '/title1', '/title2', '/title3' and '/title4' (way too descriptive for my taste /sarcasm), but for some others are '/lefttitle', '/centertitle', '/righttitle', '/outputtitle', while on Linux the options are the more explicit kind, but with a '-' instead of a '/'.
The basic things were easy, ordering the parameters in the 'source, destination, base, output' instead of kdiff3's 'base, source, destination, -o ouptut', so I wanted to add the bells and whistles, since it really makes more sense for the developer to see something like 'Destination: [method] readOptions' instead of '/tmp/tmp4327687242.tmp', and because that's exactly what is necessary for Semanticmerge when merging methods, since on conflicts the various versions of the functions are placed in temporary files which don't mean anything.
So, after some digging into the examples from Beyond Compare and kdiff3 documentation, I ended up with:
-emt="bcompare \"#sourcefile\" \"#destinationfile\" \"#basefile\" \"#output\" -lefttitle='#sourcesymbolic' -righttitle='#destinationsymbolic' -centertitle='#basesymbolic' -outputtitle='merge result'"
Sadly, I wasn't able to identify the symbolic name for the output, so I added the hard coded 'merge result'. If Codice people would like to help with with this information (or if it exists), I would be more than willing to do update the information and do the necessary changes.
Then I added the bells and whistles for the -edt and -e2mt options, so I ended up with an even more complicated command line. The end result was this monstrosity:
semanticmergetool -s=$sm_dir/src.java -b=$sm_dir/base.java -d=$sm_dir/dst.java -r=/tmp/semanticmergetoolresult.java -edt="bcompare \"#sourcefile\" \"#destinationfile\" -lefttitle='#sourcesymbolic' -righttitle='#destinationsymbolic'" -emt="bcompare \"#sourcefile\" \"#destinationfile\" \"#basefile\" \"#output\" -lefttitle='#sourcesymbolic' -righttitle='#destinationsymbolic' -centertitle='#basesymbolic' -outputtitle='merge result'" -e2mt="bcompare \"#sourcefile\" \"#destinationfile\" -savetarget=\"#output\" -lefttitle='#sourcesymbolic' -righttitle='#destinationsymbolic'"
So when I 3-way merge a function I get something like this (sorry for high resolution, lower resolutions don't do justice to the tools):
I don't expect this post to remain relevant for too much time, because after sending my feedback to Codice, they were open to my suggestion to have persistent settings for the external tool integration, so, in the future, the command line could probably be as simple as:
semanticmergetool
-s=$sm_dir/src.java -b=$sm_dir/base.java -d=$sm_dir/dst.java
-r=/tmp/semanticmergetoolresult.java
And the integration could be done via the GUI, while the command line can become a way to override the defaults.
 I have always loved
I have always loved  This year, I had slowly taken again running. It's an activity I enjoy, even though I'm far from the condition I had when I did it every day My maximum was running about 8Km four days a week (ocassionally up to 15Km, say, on weekends)... But I slowly drifted out of it over the last three years. Yes, I have taken it up now and then, but dropped out again after a few weeks.
Well, this year it felt I was getting back in the routine. Not without some gaps, but I had ran most weeks since July at least once, but usually two times. I started slowly, doing about 3Km close to home, but didn't take much to go back to my usual routes inside UNAM, doing a modest average of 4.5-5Km per run, and averaging somewhat over 8Km/h (6.5 min/Km).
But... Well, I cannot relate precisely what happened on this Exactly a month ago, after a very average run (even a short one, 3.6Km), I had a lower back ache. Didn't pay too much attention to it, but it was strange since the first day, as I often have upper back aches Never lower.
The pain came and went slowly several times. I kept cycling to work, although not every day. On October 27th, I even took the time to do the Ciclot n, a nice 38Km (including the ~5Km distance from home) around central Mexico City. I enjoyed the ride, even though every stop and re-start of the bike was a bit painful what hurts is to get off and on the bike: The posture change. But the pain has been almost constantly there. When I stand up, or when I sit down, it's about five minutes until the body gets used to the new position and stops hurting.
Another strange data point: This last weekend (together with a national holiday) we went to a small conference in Guadalajara, and then to visit our friends in Guanajuato. So, we spent 12 hours on the bus there (12 Yes, there was an accident on the road, and we could not pass... So many hours were wasted there, and going back to a junction to take an alternative, longer road), then one night in a hotel bed, and two nights in our friends' guest mattresses which are not precisely luxury-grade. And Sunday night... I had no pain at all!
Came back home, and after only one night back in our bed... I just could not move. I had the strongest pain so far. Could not even walk without some help. We went to the orthopedist a friend recommended, and I was seriously bending my posture: While that part of my posture is usually stable, my right hip was about 2cm higher than the left one, and my shoulders were almost 7cm displaced from my hips!
So... Well, I'm having a cocktail of painkillers and antiinflamatories. The doctor says next week he wants me to have a tomography taken to better understand the causes for this.
And, of course, tomorrow I'm leaving for
This year, I had slowly taken again running. It's an activity I enjoy, even though I'm far from the condition I had when I did it every day My maximum was running about 8Km four days a week (ocassionally up to 15Km, say, on weekends)... But I slowly drifted out of it over the last three years. Yes, I have taken it up now and then, but dropped out again after a few weeks.
Well, this year it felt I was getting back in the routine. Not without some gaps, but I had ran most weeks since July at least once, but usually two times. I started slowly, doing about 3Km close to home, but didn't take much to go back to my usual routes inside UNAM, doing a modest average of 4.5-5Km per run, and averaging somewhat over 8Km/h (6.5 min/Km).
But... Well, I cannot relate precisely what happened on this Exactly a month ago, after a very average run (even a short one, 3.6Km), I had a lower back ache. Didn't pay too much attention to it, but it was strange since the first day, as I often have upper back aches Never lower.
The pain came and went slowly several times. I kept cycling to work, although not every day. On October 27th, I even took the time to do the Ciclot n, a nice 38Km (including the ~5Km distance from home) around central Mexico City. I enjoyed the ride, even though every stop and re-start of the bike was a bit painful what hurts is to get off and on the bike: The posture change. But the pain has been almost constantly there. When I stand up, or when I sit down, it's about five minutes until the body gets used to the new position and stops hurting.
Another strange data point: This last weekend (together with a national holiday) we went to a small conference in Guadalajara, and then to visit our friends in Guanajuato. So, we spent 12 hours on the bus there (12 Yes, there was an accident on the road, and we could not pass... So many hours were wasted there, and going back to a junction to take an alternative, longer road), then one night in a hotel bed, and two nights in our friends' guest mattresses which are not precisely luxury-grade. And Sunday night... I had no pain at all!
Came back home, and after only one night back in our bed... I just could not move. I had the strongest pain so far. Could not even walk without some help. We went to the orthopedist a friend recommended, and I was seriously bending my posture: While that part of my posture is usually stable, my right hip was about 2cm higher than the left one, and my shoulders were almost 7cm displaced from my hips!
So... Well, I'm having a cocktail of painkillers and antiinflamatories. The doctor says next week he wants me to have a tomography taken to better understand the causes for this.
And, of course, tomorrow I'm leaving for 
 (Looking for those graphs online, I realized that I never properly published them, besides that
(Looking for those graphs online, I realized that I never properly published them, besides that 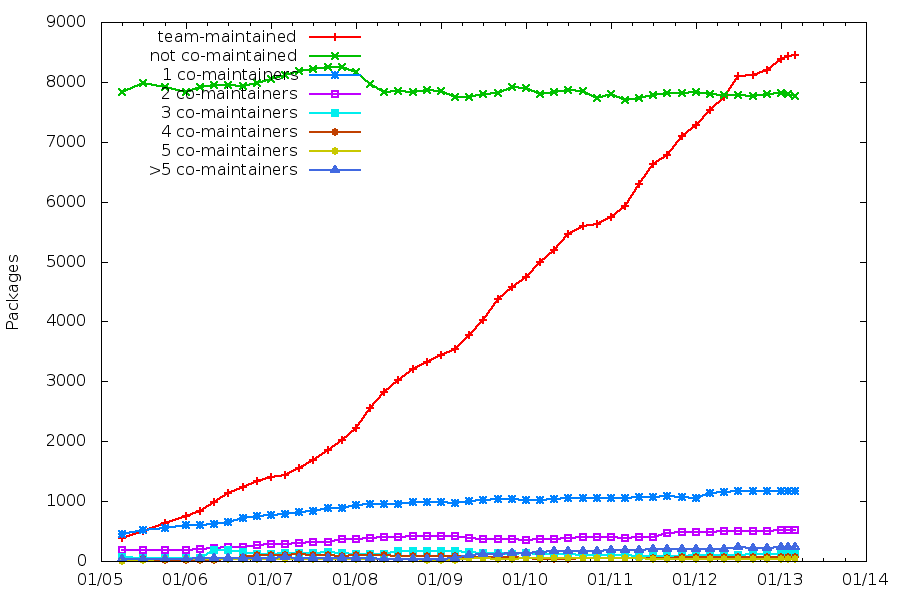
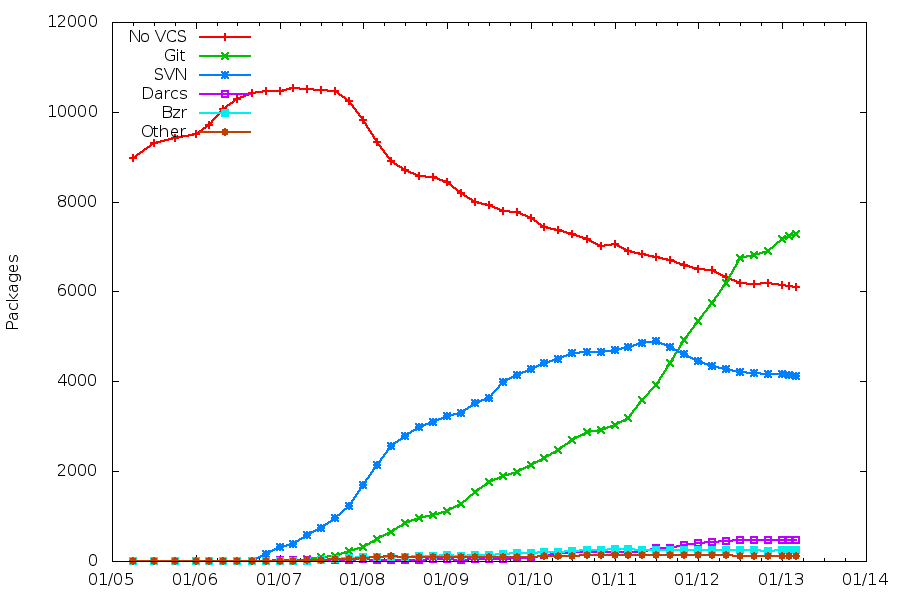 A large majority of our packages are maintained in a VCS repository, with Git being the clear winner now.
Possible goal for Jessie: standardize on a Git workflow, since every team tends to design its own?
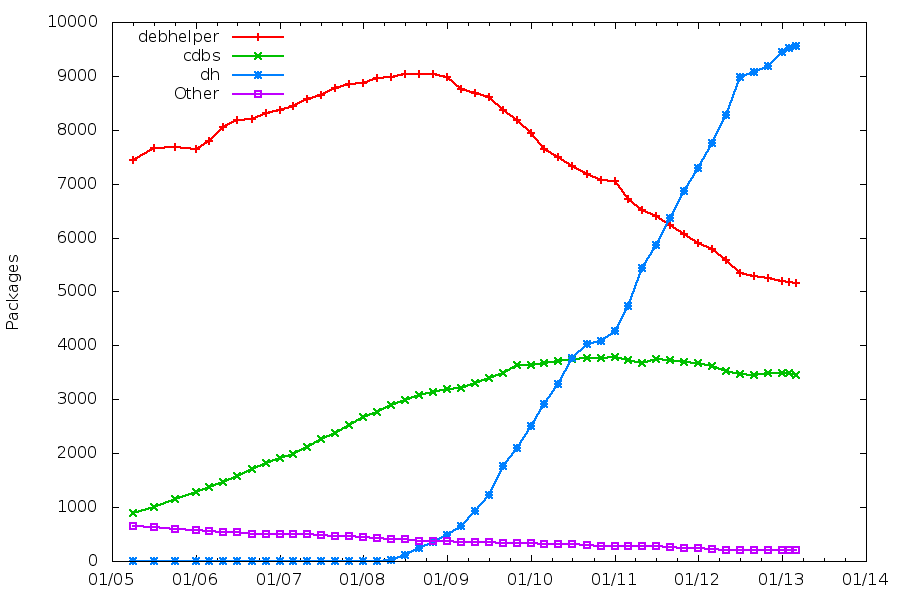
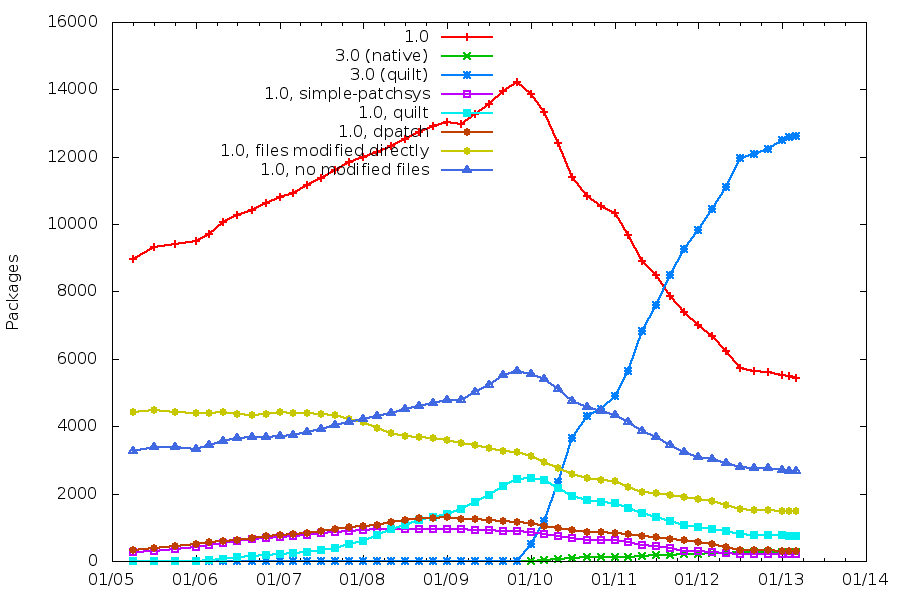
Packaging helpers
A large majority of our packages are maintained in a VCS repository, with Git being the clear winner now.
Possible goal for Jessie: standardize on a Git workflow, since every team tends to design its own?
Packaging helpers




 In May this year, in a desperate bid to bail water out of a
sinking ship,
In May this year, in a desperate bid to bail water out of a
sinking ship,  To experiment with network stuff, I was using
To experiment with network stuff, I was using

 I can't remember exactly when, it was either pre-Zoe heart-related diagnostic
imaging or during her pregnancy with Zoe, that it became apparent that Sarah
had gall stones.
Apparently it's not uncommon for women to develop them after pregnancy, and
it turns out that Sarah is slightly more genetically predisposed to getting
them to boot. So it wasn't terribly surprising when she started having some
pain recently. She had another ultrasound to confirm it, and went off to see
a surgeon.
Apparently they care more about the symptoms than the number of stones in
the gallbladder, and they don't bother removing the stones and keeping the
gallbladder, so she was booked in for a cholecystectomy last Thursday.
It was a pretty straightforward procedure, she was out of the operating room
in just under an hour, and awake a bit over an hour after that.
I've had a few friends need to have a cholecystectomy, and the photos on
Wikipedia have always fascinated me, particularly
I can't remember exactly when, it was either pre-Zoe heart-related diagnostic
imaging or during her pregnancy with Zoe, that it became apparent that Sarah
had gall stones.
Apparently it's not uncommon for women to develop them after pregnancy, and
it turns out that Sarah is slightly more genetically predisposed to getting
them to boot. So it wasn't terribly surprising when she started having some
pain recently. She had another ultrasound to confirm it, and went off to see
a surgeon.
Apparently they care more about the symptoms than the number of stones in
the gallbladder, and they don't bother removing the stones and keeping the
gallbladder, so she was booked in for a cholecystectomy last Thursday.
It was a pretty straightforward procedure, she was out of the operating room
in just under an hour, and awake a bit over an hour after that.
I've had a few friends need to have a cholecystectomy, and the photos on
Wikipedia have always fascinated me, particularly 


{kind=link}